(本貼文所列出的程式碼,皆以 colab 筆記本方式執行,[可由此下載]
(https://colab.research.google.com/drive/1g5BmTsItir8neTA59wvYzvrDqbbM_4aK?usp=sharing)
偏微分及導數 (或梯度) 的計算,是現今機器學習 (及深度學習) 演算法在模型訓練時,最重要的運算之一,JAX 提供了「自動微分 Auto Diff」功能來支援這一類的運算。
JAX 的自動微分,其實來自於 Autograd [26.1]。Autograd 是 Google 支持的一個開源專案,其目的在於針對 Python 及 Numpy 程式,提供方便的梯度計算 API。JAX 沿用了原來的 Autograd,並將其封裝在 jax.grad() 裏,除了原來對 Python 和 Numpy 的支援外,當然也對 JAX 獨特的功能 (如 DeviceArray,控制流程等) ,優化原始的 Autograd。目前原始 Autograd 的人力大多轉移到 JAX 上了,Google 僅做於維護的工作,並不會對它進行升級。
我想大部份的 JAX 讀者應該跟老頭一樣,在開始研究 JAX 之前,並沒有接觸過 Autograd,因此在這個地方,老頭先把步調放慢,從一些簡單的範例程式,一步步帶大家認識 jax.grad()。
按:在 JAX 好好玩系列裏,老頭直接介紹 jax.grad(),並不會對原來的 Autograd 多所著墨,此後,貼文中如果提到 Autograd,除非特別說明,否則都是指 JAX 中的 jax.grad() 相關 API。
先複習一下高中數學 
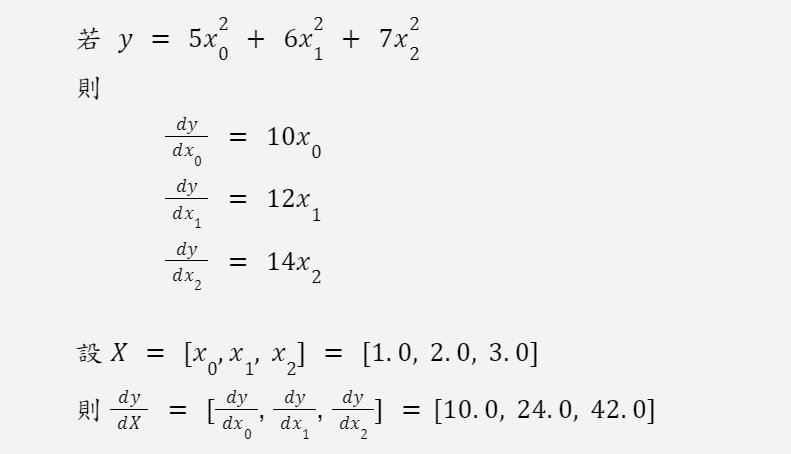
我們可以利用 jax.grad() 來實作上面的導數計算:
def y(X):
return 5*(X[0]**2) + 6*(X[1]**2) + 7*(X[2]**2)
X = jnp.array([1.0, 2.0, 3.0])
jax.grad(y)(X)
output:
DeviceArray([10., 24., 42.], dtype=float32)
以上的程式片段中,X是一個陣列,而 jax.grad(y)(X) 會分別對 X 陣列內的每一個元素,求其函式 y 的導數 (偏微分),並且回傳導數陣列。
另外一種寫法是:
def yy(x1, x2, x3):
return 5*(x1**2) + 6*(x2**2) + 7*(x3**2)
X = jnp.array([1.0, 2.0, 3.0])
jax.grad(yy, argnums=(0,1,2))(X[0], X[1], X[2])
output:
(DeviceArray(10., dtype=float32),
DeviceArray(24., dtype=float32),
DeviceArray(42., dtype=float32))
jax.grad() 預設只對函式的第一個參數 (以上例為 x1) 求導數,argnums=(0,1,2) 則表示要對前三個 (即參數索引 0, 1 及 2) 輸入參數求導數。而回傳值為含有三個元素的 tuple,分別對應輸入參數 x1, x2, x3。
又假設我們只想對第一和第三個輸入參數求導數,可以這麼寫:
jax.grad(yy, argnums=(0,2))(X[0], X[1], X[2])
output:
(DeviceArray(10., dtype=float32), DeviceArray(42., dtype=float32))
jax.grad 可以和 jax.jit 結合,以加快導數計算的效率。我們知道,在深度學習模型訓練的時候,反向傳導演算法 (backpropagation) 需要大量的偏微分計算,所以這樣子的結合,可以有效減少機器模型在訓練時所需要的時間。
先看未結合前的計算時間:
%timeit jax.grad(y)(X)
output:
24.6 ms ± 4.46 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
再看看結合後所需的時間:
git_grad_fun = jax.jit(jax.grad(y))
git_grad_fun(X) # to trace the function once
%timeit git_grad_fun(X) # without tracing
output:
72.4 µs ± 4.89 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
若不計追踪的時間,上述的例子,使用 JIT 會有 300 多倍的速度提升!!
註:
[26.1] Autograd GitHub project link


 iThome鐵人賽
iThome鐵人賽